
Modern engineering teams face increasing pressure to deliver systems that are faster, more scalable, and more reliable—all while reducing toil. This is exactly where Agentic AI workflows transform the way Site Reliability Engineering (SRE) operates. Agentic AI doesn’t just automate tasks; it understands context, makes decisions, takes actions, and continuously improves. When applied properly, an Agentic AI workflow becomes a powerful reliability layer embedded across systems, operations, and engineering processes.
Want deeper insights? Read our full guide on Agentic AI SRE: Smarter, Faster Reliability Excellence.
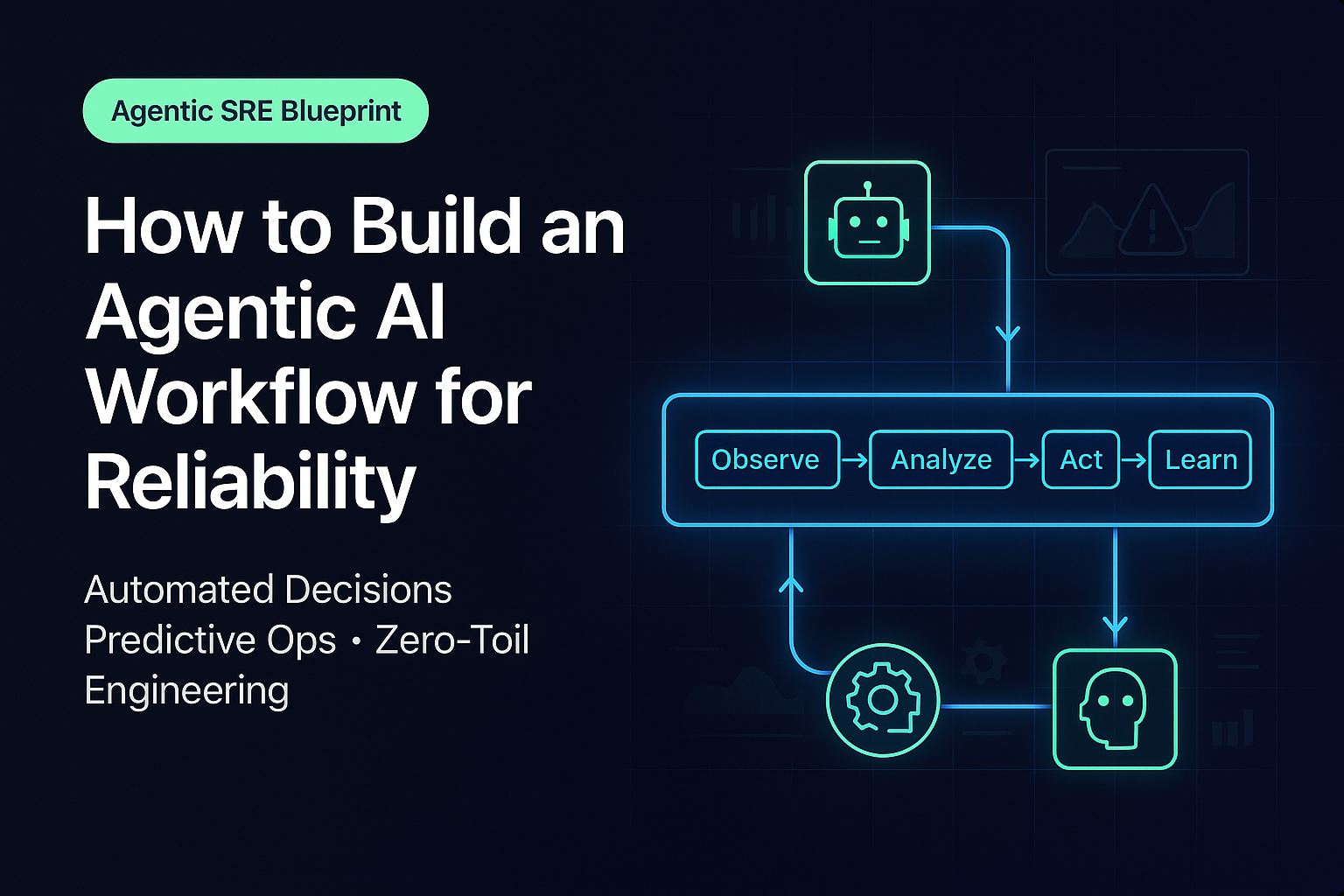
Here’s how to build an effective, production-grade Agentic AI workflow for reliability.
1. Start with Clear Reliability Objectives
Before integrating AI into your reliability processes, you must define SLIs, SLOs, and error budgets. Agentic AI relies on clear metrics to evaluate system health and trigger actions.
For example:
Latency SLI: p95 < 150 ms
Reliability SLO: 99.9%
Error Budget: 43 minutes per month
These goals help your AI agents determine what actions are safe, urgent, or unacceptable. Without this foundation, AI may act in a way that conflicts with your reliability strategy.
2. Build a Multi-Layer Observability System
Agentic AI requires structured, real-time data to make autonomous decisions. Your observability stack should include:
Metrics (Prometheus, Datadog)
Logs (ELK, Loki)
Traces (Jaeger, OpenTelemetry)
Events (Kafka, Pub/Sub)
AI agents use these streams to understand trends, detect anomalies, predict failures, and recommend or execute actions. The richer your observability, the smarter your AI.
3. Implement a Decision-Making Engine
This is the core of an Agentic AI workflow.
Your decision engine should contain:
Rules (threshold breaches, SLO violations)
Policies (what AI can or cannot do)
AI Models for prediction, anomaly detection, and impact analysis
LLM-based reasoning for multi-step decisions
For example, if latency spikes due to a service overload, the AI agent may choose between autoscaling, shedding traffic, or rolling back a release—based on reliability policies and predicted outcomes.
4. Integrate Autonomous Action Pipelines
Once the AI agent decides what to do, it must be able to execute it safely.
This requires connecting AI to:
CI/CD pipelines
Runbooks and workflows
Kubernetes controllers
Incident management systems
Infrastructure APIs
Actions can include:
Autoscaling pods
Redeploying a stable version
Restarting failed services
Running diagnostic scripts
Opening an incident ticket
The key is to implement human-in-the-loop controls for high-risk actions and fully autonomous execution for low-risk, repeatable tasks.
5. Add Continuous Learning Loops
Reliability improves only when the system learns from incidents and outcomes. Agentic AI should incorporate:
Post-incident summaries
Pattern recognition
Policy updates based on past failures
Improvement of models via feedback
The more feedback the system gets, the more accurate and reliable it becomes.
6. Ensure Governance, Security & Guardrails
Agentic AI must operate within strict safety boundaries. This includes:
Access control
Auditing
Action approvals
Rate limiting
Compliance checks
A well-governed AI workflow builds trust among SRE teams and prevents operational risks.
Why SRE Foundation Certification Is Important
The SRE Foundation certification is valuable because it helps professionals understand the core principles required to build and manage reliability-focused AI workflows. Concepts like SLIs/SLOs, error budgets, automation, incident response, and resilience engineering are fundamental to designing an Agentic AI system. Without this knowledge, teams may over-automate, overlook risk, or misalign AI actions with business reliability goals. The certification ensures that engineers and architects have a solid reliability mindset, enabling them to use agentic systems safely, strategically, and effectively.